2025年10月30日,北京大学光华管理学院商务统计与经济计量系和北京大学统计科学中心联席教授涂云东应邀为我校师生作题为“HFFV: Hierarchical Factor-Augmented Forward-Validation Model Averaging Forecasting with Distributed High-Dimensional Time Series”的学术讲座。讲座于学院11号楼115教室举行,多位院内外教师及近30名同学参加了此次活动。
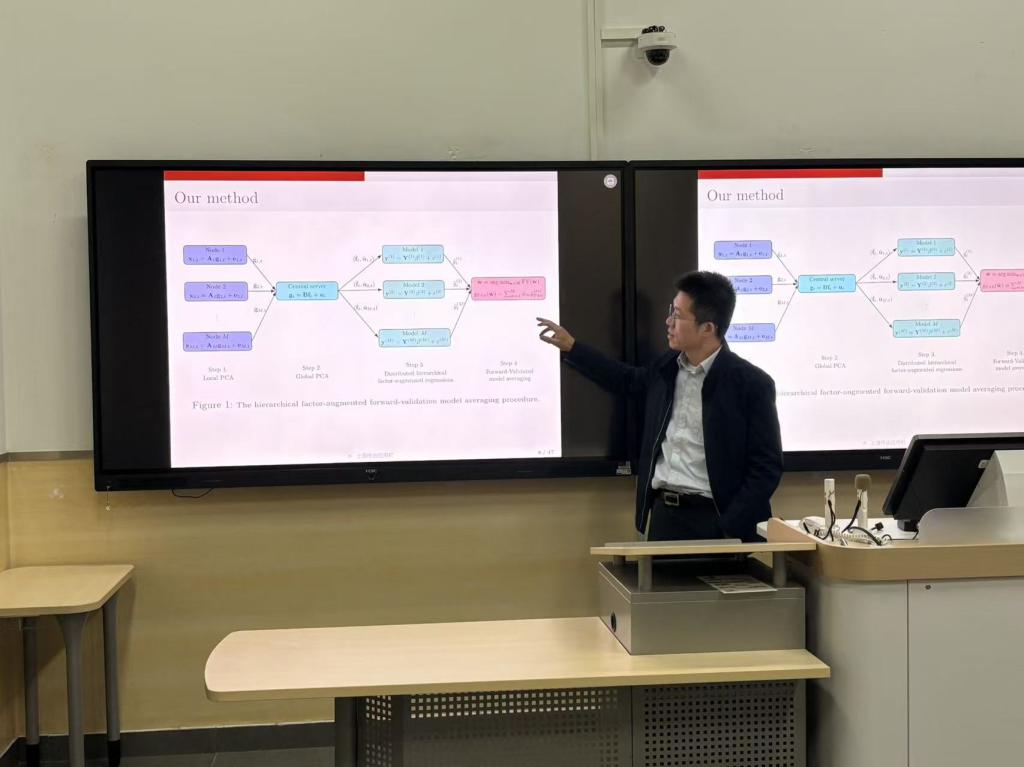
涂云东教授从高维时间序列分析中的现实挑战切入。随着数据维度和时间跨度的不断扩大,传统的集中式建模方法往往需要将所有数据汇总至一台“中央服务器”进行主成分分析(PCA)或因子提取,再进行因子增广回归(FAR)。然而,当数据量极大或分布于不同物理节点时,单台机器的内存与算力难以支撑这一过程,同时还会面临数据安全与合规风险。因此,传统的“中央式”因子建模在技术与实践中存在一定的局限性。
针对上述问题,涂云东教授提出了一种HFFV(Hierarchical Factor-Augmented Forward-Validation)方法。HFFV模型采用层级化因子结构:首先在各节点内部提取“组内因子”,再在全局层面提取“全局因子”,从而兼顾局部特征与整体趋势。随后,模型基于前向验证(Forward-Validation)准则对各节点的预测模型进行加权平均,形成最终的预测结果。理论分析表明,该方法在模型设定正确和设定错误的情形下均具有渐近最优性和权重选择一致性。模拟结果进一步显示,HFFV在大多数设定下均优于现有的分布式预测方法,尤其在组内因子对目标变量影响较大时表现更加突出。该方法通过在各数据节点本地提取因子,并仅将低维的局部因子信息汇总至中心节点,显著降低了数据传输负担,同时有效保护了原始数据隐私。
在讲座的问答环节中,与会师生就HFFV方法在中国数据中的实证研究及该方法与传统因子模型的具体差异。讲座在热烈的学术氛围中结束。与会师生对分布式数据与高维时间序列建模的最新研究进展与应用实践有了更深层次的了解。
撰稿人:崔雨濛
审稿人:郭冬梅、黄乃静

 院长信箱
院长信箱
 书记信箱
书记信箱
 English
English
